
Inhoudsopgave
Kunstmatige Intelligentie (KI) of in het Engels Artificial intelligence (AI) is het vermogen van computers om taken uit te voeren waarvoor mensen hun intelligentie inzetten. Kunstmatige intelligentie vindt je tegenwoordig overal om je heen. Naast de bekende schaakcomputer kun je ook denken aan zelfrijdende auto’s, google die alle gevonden websites op relevantie presenteert of programma’s die zonder tussenkomst van de mens de waardeontwikkeling van aandelen voorspelt.
1 Wat is Artificial Intelligence?
Hoe we werk vinden, hoe we online winkelen, hoe vriendschappen en liefdes ontstaan, welke nieuwsartikelen en films we kijken, hoe computers steeds meer taken van de mensen overnemen heeft allemaal te maken met kunstmatige intelligentie. Ons dagelijks leven wordt steeds meer beïnvloedt door kunstmatige intelligentie. Maar wat is dat nu eigenlijk, artificial intelligence?
1a Definities
Er zijn boekenkasten vol geschreven over wat kunstmatige intelligentie of artificial intelligence nu precies is. Een alomvattende definitie van kunstmatige intelligentie ontbreekt echter nog. Daarom zijn hieronder een aantal definities weergegeven op basis waarvan je een goed idee krijgt wat kunstmatige intelligentie precies is.
- Kaplan en Haenlein: “Artificial Intelligence is het vermogen van een systeem om externe gegevens correct te interpreteren, om te leren van deze gegevens, en om deze lessen te gebruiken om specifieke doelen en taken te verwezenlijken via flexibele aanpassing.”
- Encyclopedie; “kunstmatige intelligentie is de bestudering van het vermogen van machines om menselijk gedrag zoals waarnemen, redeneren, leren of het begrijpen van spraak, na te bootsen.”
- Jarno Duursma; “kunstmatige intelligentie is het concept dat machines taken kunnen uitvoeren op een manier die wij mensen als ‘slim’ zouden beoordelen omdat we vinden dat ze toebehoren aan menselijke intelligentie.”
Bij kunstmatige intelligentie gaat het dus om machines (of computersystemen) die taken uitvoeren die kenmerkend zijn voor mensen. Machines met het vermogen om te redeneren, betekenis te ontdekken, te generaliseren of te leren van ervaringen uit het verleden. Waarbij kunstmatige intelligentie sterk tijdsgebonden is. Daar waar de rekenmachine 60 jaar geleden als kunstmatige intelligentie werd beschouwd doen we dat nu niet meer. Als we het vandaag de dag over kunstmatige intelligentie hebben doelen we op zelflerende systemen zoals de zelfrijdende auto of de wijze waarop Google de volgorde van de resultaten van een zoekopdracht weergeeft.
1b Voordelen Artificial Intelligence
Kunstmatige intelligentie bestaat al sinds jaar en dag. Van de rekenmachine, de spelcomputer en snelle suggesties voor zoekmachines tot digitale hulp (chatbots) op internet en cruise control voor voertuigen. Kunstmatige intelligentie maakt steeds meer een onderdeel uit van ons dagelijks leven. Maar waarom integreren we steeds meer artificial intelligence in ons dagelijks leven? Hieronder staan de 10 grootste voordelen van artificial intelligence opgesomd:
- Verhogen productiviteit; door inzet van kunstmatige intelligentie worden repeterende taken geautomatiseerd waardoor deze taken beter en goedkoper worden uitgevoerd. Automatisering maakt multitasking mogelijk en verlicht de werklast voor de mens. Denk hierbij zowel aan de meer simpele vormen van kunstmatige intelligentie (zoals de lopende band en kantoorautomatisering) tot aan meer intelligente computers die bijvoorbeeld nauwkeurig het weer voorspellen of risicoprofielen opstellen ten behoeve van fraudeprotectie.
- Beschikbaarheid van 24*7; machines of computers worden niet moe, zijn makkelijk schaalbaar, kennen geen stress, worden niet ziek en raken niet verveeld. Ze hebben geen moeite met het opvolgen van instructies en hoeven niet om 17.00 uur naar huis. Een machine is 24*7 productief en kan daardoor makkelijker schommelingen
 in productie opvangen dan wanneer de mens deze taken uitvoert. Hiermee wordt de afhankelijkheid van de (productiefactor) mens kleiner.
in productie opvangen dan wanneer de mens deze taken uitvoert. Hiermee wordt de afhankelijkheid van de (productiefactor) mens kleiner. - Betere en snellere besluitvorming; kunstmatige intelligentie is beter en sneller in staat om beslissingen te maken. Een sprekend voorbeeld hiervan is de schaakcomputer. Nadat de tegenstander een zet heeft gedaan doet de schaakcomputer binnen 2 seconden een tegenzet. In de zekerheid dat de schaakcomputer ook nog eens gaat winnen. Omdat kunstmatige intelligentie (onder voorwaarden) beter en sneller kan beslissen wordt KI steeds vaker ingezet voor het doorrekenen van strategische opties of het doen van scenarioanalyses.
- Risicovolle taken uitvoeren; kunstmatige intelligentie biedt de mogelijkheid om risico’s die de mens loopt bij het uitvoeren van haar werkzaamheden te beperken. We kennen allemaal de robot die bommen op afstand onschadelijk maakt. Maar je kunt ook kunstmatige intelligentie inzetten voor het delven van grondstoffen of het aansluiten van gasleidingen. Kunstmatige intelligentie wordt steeds vaker ingezet voor taken die voor de mens gevaarlijk zijn om uit te voeren.
- Hogere medewerkerstevredenheid; door repeterende taken te automatiseren kan de mens zich richten op de meer leuke en complexe taken waar de tussenkomt van de mens (nog) nodig is. Dit leidt tot een grotere medewerkerstevredenheid en minder stress op de werkvloer. Daarnaast nemen machines steeds vaker de fysieke zware werkzaamheden over. Dit is goed voor de welzijn van de medewerker. En daarbij wordt de kans op ziekte kleiner.
- Minimaliseren van (menselijke) fouten; een machine of computer maakt geen fouten. Door het automatiseren van taken wordt de kans op handmatige fouten minimaal. Als er toch fouten worden gemaakt door de machine dan heeft dat te maken met de onderhoud van de machine of de kwaliteit van het programma dat op die machine of computer draait. In beide gevallen ligt de fout dan toch bij de mens en niet bij de machine (of computersysteem).
- Medische vooruitgang; het gebruik van artificial intelligence-oplossingen in de zorg zien we in steeds meer verschillende toepassingen terug. Dankzij technologie voor patiëntbewaking op afstand kunnen zorgverleners bijvoorbeeld snel klinische diagnoses stellen en behandelingen voorstellen zonder dat de patiënt naar het ziekenhuis hoeft. Kunstmatige intelligentie kan ook nuttig zijn bij het volgen van de progressie van besmettelijke ziekten zoals bij Corona het geval is. Zo baseert het RIVM haar voorspellingen op kunstmatige intelligentie.
- Gegevens- en scenarioanalyse; kunstmatige intelligentie wordt ook gebruikt om grote hoeveelheden data te analyseren. Denk bijvoorbeeld aan het opstellen van risicoprofielen van fraudeurs door verschillende datasets (politie, belastingdienst, justitie) aan elkaar te koppelen. Verder kan AI helpen bij het maken van voorspellende modellen en algoritmen om gegevens te verwerken en de mogelijke uitkomsten van verschillende
 trends en scenario’s te begrijpen. Zo zijn er computerprogramma’s die op basis van real time informatie de waarde van de ontwikkeling van aandelen en obligaties voor die dag voorspellen.>
trends en scenario’s te begrijpen. Zo zijn er computerprogramma’s die op basis van real time informatie de waarde van de ontwikkeling van aandelen en obligaties voor die dag voorspellen.> - Persoonlijke hulpverlening; kunstmatige intelligentie helpt organisaties om snel in te spelen op vragen en klachten van klanten of burgers. Met gebruik van chatbots (die op basis van Natural Language Processing-technologie vragen van een klant vertalen in computertaal) kan zonder tussenkomst van de mens een oplossing worden gegeven op de specifieke vraag van de klant. Met kunstmatige intelligentie is de klant geen ‘nummer’ meer. In communicatie met de klant wordt ingegaan op de persoonlijke situatie van de klant. AI-tools maken het mogelijk betere dienstverlening tegen lagere kosten te leveren.
- Nieuwe uitvindingen; kunstmatige intelligentie wordt tot op heden vaak ingezet om taken van medewerkers over te nemen of te vereenvoudigen. Kunstmatige intelligentie beschikt echter over eigenschappen waarover de mens niet beschikt. Zoals een bijna onbegrensde verwerkingscapaciteit. Daardoor kunnen we met kunstmatige intelligentie complexe problemen vraagstukken oplossen waar dit voorheen nog niet mogelijk was. Bijvoorbeeld het opstellen van een individueel risicoprofiel van een burger. Of het voorspellen van de kans tot het krijgen van een specifieke ziekte, zoals kanker of Alzheimer, op basis van analyse van DNA-profielen.
 in productie opvangen dan wanneer de mens deze taken uitvoert. Hiermee wordt de afhankelijkheid van de (productiefactor) mens kleiner.
in productie opvangen dan wanneer de mens deze taken uitvoert. Hiermee wordt de afhankelijkheid van de (productiefactor) mens kleiner. trends en scenario’s te begrijpen. Zo zijn er computerprogramma’s die op basis van real time informatie de waarde van de ontwikkeling van aandelen en obligaties voor die dag voorspellen.>
trends en scenario’s te begrijpen. Zo zijn er computerprogramma’s die op basis van real time informatie de waarde van de ontwikkeling van aandelen en obligaties voor die dag voorspellen.>Er zijn nog veel meer voordelen en/of mogelijkheden van kunstmatige intelligentie, variërend van verkenning van de ruimte tot verbeteringen in militaire verdedigingssystemen. Artificial intelligence ontwikkelt zich gestaag en zal steeds intelligenter worden. Het is dan ook zeker dat AI een steeds groter impact gaat krijgen op onze manier van leven. We weten alleen nog niet precies hoe. Omdat we als mens met onze beperkte brein nog niet goed in kunnen schatten wat het ware potentieel is van kunstmatige intelligentie.
1c Wat is (Computer)intelligentie?
Om kunstmatige intelligentie te begrijpen is het noodzakelijk om inzicht te hebben in de intelligentie van de mens. Dieren kennen geen intelligentie omdat zijn uitsluitend instinctief gedrag vertonen. De intelligentie van de mens omvat juist het vermogen om instinctieve reacties te onderdrukken. Intelligentie van de mens bevat het vermogen om zich aan te passen aan nieuwe omstandigheden. Onderzoek naar artificial intelligence heeft zich voornamelijk gericht op de volgende componenten van intelligentie: leren, redeneren, probleemoplossing, perceptie en taalgebruik.
- Leren; er zijn een aantal verschillende vormen van leren die je ook kunt toepassen op kunstmatige intelligentie. De eenvoudigste manier van leren is leren door vallen en opstaan. Een goed voorbeeld is een schaakcomputer die onthoudt dat een bepaalde zet in een bepaalde positie tot schaakmat leidt. De schaakcomputer zal de volgende keer een ander zet doen. Wat wil zegen dat een computer op basis van ervaringen in het verleden zijn eigen algoritme kan aanpassen zodat het in de toekomst beter kan presteren.
- Redeneren; redeneren is conclusies trekken die bij de situatie passen. Kernbegrippen hierbij zijn deductie en inductie. Deductie betekent dat vanuit een algemene regel een conclusie wordt getrokken voor een bijzonder geval.
 Bijvoorbeeld alle mensen zijn sterfelijk. Piet is een mens. Conclusie: Piet is sterfelijk. Tegenover deductie staat inductie. Waarbij op grond van enkele bijzondere gevallen een algemene conclusie wordt getrokken. Je kunt een computer leren om te redeneren door het algoritme zo te coderen dat het computersysteem algemene conclusies trekt uit relaties tussen afzonderlijke gegevens.
Bijvoorbeeld alle mensen zijn sterfelijk. Piet is een mens. Conclusie: Piet is sterfelijk. Tegenover deductie staat inductie. Waarbij op grond van enkele bijzondere gevallen een algemene conclusie wordt getrokken. Je kunt een computer leren om te redeneren door het algoritme zo te coderen dat het computersysteem algemene conclusies trekt uit relaties tussen afzonderlijke gegevens. - Problemen oplossen; wordt gedefinieerd als een systematische zoektocht naar een reeks mogelijke acties om een vooraf gedefinieerd doel of oplossing te bereiken. Een algemene techniek die binnen kunstmatige intelligentie hiervoor wordt gebruikt, is middel-eindanalyse: een stapsgewijze of incrementele verkleining van het verschil tussen de huidige staat en het uiteindelijke doel. Het programma selecteert acties uit een lijst met middelen – in het geval van een eenvoudige robot dit kan bestaan uit Pickup, Putdown, Moveformward, Moveback, Moveleft en Moveright, totdat het doel is bereikt.
- Waarnemen; bij deze vorm van intelligentie wordt met behulp van zintuigen de omgeving afgetast. En wordt de omgeving opgesplitst in afzonderlijke objecten in verschillende ruimtelijke relaties. Analyse wordt bemoeilijkt door het feit dat een object er anders uit kan zien, afhankelijk van de hoek van waaruit het wordt bekeken, de richting en intensiteit van de verlichting in de scène en hoeveel het object contrasteert met het omringende veld. Bij artificial intelligence worden de menselijke zintuigen vervangen door sensoren. Zo zitten zelfrijdende auto’s tot de nok toe vol met sensoren.
- Taal; is een systeem van tekens die volgens afspraak een betekenis hebben. Dat kan gaan om vogelgeluiden of om verkeersborden. Een belangrijk kenmerk van volwaardige mensentalen is – in tegenstelling tot vogelgeluiden en verkeersborden – hun productiviteit. Een productieve taal kan een onbeperkt aantal zinnen formuleren. Computersystemen zijn op basis van kunstmatige intelligentie steeds beter in staat om te praten als de mens. Op basis van analyse van miljoenen of miljarden voorbeelden (big data) weet de computer wat die moet zeggen. De vraag is echter of de computer ooit leert om taal ook echt te begrijpen. Omdat taal mede zijn oorsprong vindt in culturele historie en interactie met andere mensen.
 Bijvoorbeeld alle mensen zijn sterfelijk. Piet is een mens. Conclusie: Piet is sterfelijk. Tegenover deductie staat inductie. Waarbij op grond van enkele bijzondere gevallen een algemene conclusie wordt getrokken. Je kunt een computer leren om te redeneren door het algoritme zo te coderen dat het computersysteem algemene conclusies trekt uit relaties tussen afzonderlijke gegevens.
Bijvoorbeeld alle mensen zijn sterfelijk. Piet is een mens. Conclusie: Piet is sterfelijk. Tegenover deductie staat inductie. Waarbij op grond van enkele bijzondere gevallen een algemene conclusie wordt getrokken. Je kunt een computer leren om te redeneren door het algoritme zo te coderen dat het computersysteem algemene conclusies trekt uit relaties tussen afzonderlijke gegevens.Als we het over artificial intelligence hebben dan hebben we het over het toevoegen van intelligentie aan machines. We voegen menselijke eigenschappen van hoe je moet leren, redeneren, problemen oplossen, waarnemen en taal toe aan het algoritme van de computer.
1d Kunstmatige Intelligentie = Algoritme + Data
Artificial intelligence bestaat uit 2 elementen: een algoritme en data. Een algoritme is een reeks van instructies die leidt tot een bepaald resultaat. Dit klinkt heel abstract, maar de aanbevelingen om verder te kijken van een streaming videodienst als Netflix zijn gebaseerd op een algoritme. Aan de hand van ons kijkgedrag leert Netflix wat we interessant vinden en doet op basis daarvan een aantal aanbevelingen. Om die aanbevelingen te kunnen doen, is data nodig.  In dit geval ons eigen kijkgedrag én dat van anderen. Data is de grondstof die algoritme laat werken. Door meer data te analyseren kan het algoritme betere aanbevelingen doen.
In dit geval ons eigen kijkgedrag én dat van anderen. Data is de grondstof die algoritme laat werken. Door meer data te analyseren kan het algoritme betere aanbevelingen doen.
Waarbij de aanbevelingen die Netflix doet gebaseerd is op de meest eenvoudige vorm van artificial intelligence. Het algoritme (het computerprogramma) geeft namelijk maar antwoord op één vraag. Namelijk welke film of serie zal de kijker waarschijnlijk interessant vinden. Het algoritme is redelijk simpel en de dataset is beperkt. Je kunt je voorstellen dat bij een rijdende auto de algoritmes vele malen complexer zijn en de dataset extreem groot is. De essentie van artificial intelligence is het steeds slimmer maken van deze algoritmes
1e Drie niveaus van Artificial Intelligence
Artificial Intelligence is het vermogen van computers om taken uit te voeren waarvoor mensen hun intelligentie inzetten. Waarbij het algoritme aangeeft welke instructies uitgevoerd moeten worden om de taak goed te vervullen. We onderscheiden drie niveaus van kunstmatige intelligentie.
- Toegepaste AI (ook wel zwakke AI genoemd); we hebben het dan over de zogenaamde expertsystemen of kennissystemen waarbij één taak die voorheen door de mens werd uitgevoerd door de computer wordt uitgevoerd. Deze expertsystemen richten zich op één enkel probleem of geven antwoord op één specifieke vraag. Deze expert systemen kunnen dit soort vraagstukken veelal beter oplossen dan de mens omdat de mens maar een beperkte hoeveelheid gegevens kan verwerken. Voorbeelden van zwakke AI zijn:
- Schaakcomputer
- Microsoft Office (Word, Excel, Power point)
- Boekhoud-, Planning en Logistieke systemen
- Zelfrijdende auto’s
- Spraak & Gezichtsherkenning
- Email spam filters
- Sterke AI (ook wel algemene AI genoemd); sterke AI heeft als doel machines te bouwen die zelf ‘denken’. Bij sterke AI kan een machine de intelligentie van de mens nabootsten. Zo kan sterke AI meerdere problemen of vraagstukken analyseren, beoordelen en voorzien van een antwoord. En kan sterke kunstmatige intelligentie omgaan met onverwachte situaties. Sterke AI blijkt echter extreem lastig te zijn om te realiseren. Menselijke eigenschappen als intuïtie, herinneringen, verbeelding en herkenning blijken in de praktijk (vooralsnog) niet om te zetten in algoritmes. Sommige critici betwijfelen of onderzoek in de nabije toekomst zelfs maar een systeem zal opleveren met het algemene intellectuele vermogen van een mier. Sommige onderzoekers vinden daarom sterke AI niet de moeite waard om na te streven.
- Super AI; we spreken van kunstmatige superintelligentie als AI de menselijke intelligentie overstijgt en de machine zelfbewust wordt. Kunstmatige superintelligente is een vervolg op de ontwikkeling van sterke AI. Omdat sterke AI nog in de kinderschoenen staat is het moeilijk in te schatten of en wanneer er machines ontstaan met kunstmatige superintelligentie. Hypothetisch zou het bouwen van die ene machine het laatste kunnen zijn wat de mens nog op technisch gebied hoeft te doen. Die machine is zo superintelligent dat ze zelf weernieuwe slimme machines kunnen creëren.
De AI zoals we die nu kennen en gebruiken is de meest zwakke vorm van AI. Desalniettemin is de impact van deze ‘zwakke vorm van AI’ op onze manier van leven nu al enorm groot. Denk daarbij aan alle mogelijk computer(programma’s) die veel van de werkzaamheden, die voorheen door de mensen werden uitgevoerd, hebben overgenomen. En op het moment dat er sprake is van sterke AI (of zelfs kunstmatige superintelligentie) dan zal deze impact alleen nog maar groter worden.
1f De Turing Test
Er bestaat veel discussie over wanneer sprake is van kunstmatige intellengtie. Wanneer beschikt een computer (machine) over intelligentie die eigenlijk toebehoort aan de mens? Valt de rekenmachine onder deze definitie? Of hebben we het bij kunstmatige intelligentie alleen over zelflerende systemen of machines die zelf kunnen denken? En wat verstaan we daar dan onder? In 1950 omzeilde Turing deze discussie over wat kunstmatige intelligentie nu precies is en introduceerde een praktische test voor computerintelligentie die bekend staat als de Turing-test. Bij de Turing-test stelt een ondervrager vragen aan zowel een mens  als een computer. De ondervrager probeert, door vragen te stellen en de antwoorden te beoordelen, vast te stellen welke van de twee de computer is. Waarbij alle communicatie via toetsenbord en beeldscherm verloopt om zo andere menselijke eigenschappen uit te sluiten (bijvoorbeeld uiterlijk of spraak). Een computer (of machine) slaagt voor de Turing test als de ondervrager op basis van de antwoorden geen onderscheid kan maken tussen de mens en de computer.
als een computer. De ondervrager probeert, door vragen te stellen en de antwoorden te beoordelen, vast te stellen welke van de twee de computer is. Waarbij alle communicatie via toetsenbord en beeldscherm verloopt om zo andere menselijke eigenschappen uit te sluiten (bijvoorbeeld uiterlijk of spraak). Een computer (of machine) slaagt voor de Turing test als de ondervrager op basis van de antwoorden geen onderscheid kan maken tussen de mens en de computer.
De Turing test is dé test om vast te stellen of een machine over kunstmatige intelligentie beschikt of niet. Waarbij de test ook nog eens makkelijk is uit te voeren. Op de test valt wel het nodige af te dingen. De test richt zich met name op geautomatiseerde gesprekken. Een belangrijk onderdeel van kunstmatige intelligentie maar er zijn meerdere verschijningsvormen van KI. Daarbij heeft nog geen enkele computer de test doorstaan. Althans, als je de strikte voorwaarden van de test aanhoudt. Tenslotte verandert in de tijd de interpretatie van wat kunstmatige intelligentie nu precies is. Zo werd in de jaren ’60 van de vorige eeuw de rekenmachine als kunstmatige intelligentie beschouwd. Terwijl we daar nu niet meer van onder de indruk zijn.
2 Machine Learning en Deep learning
Begrippen als artificial intelligence, machine learning en deep learning worden vaak door elkaar heen gebruikt. En hoewel deze begrippen aan elkaar zijn gerelateerd zijn het wel degelijk verschillende concepten. Bij kunstmatige intelligentie gaat het om alle soorten machines die een vorm van intelligentie vertonen. Het gaat hierbij om eenvoudige rekenmachines tot zelfbewuste systemen. Bij machine learning en deep learning hebben we het alleen over systemen die beschikken over zelflerend vermogen. Of over systemen die over eigen intelligentie of zelfbewustzijn beschikken. In onderstaand figuur wordt de relatie tussen artificial intelligence en machine learning duidelijk.
Machine Learning
Machine learning is een specifieke vorm van artificial intelligence. Bij machine learning leren computers zichzelf aan, zonder tussenkomst van de mens, om steeds beter te presteren. Computers passen zelfstandig hun algoritmes aan om de prestaties te verbeteren. Machine learning leunt daarbij zwaar op complexe algoritmes, statistische analyse en datamining (big data). We onderscheiden daarbij de volgende vormen van machine learning
- Supervised machine learning; deze vorm van machine learning vindt ‘onder toezicht’ van de mens plaats. Door gebruik van door de mens gelabelde datasets wordt het algoritme geleerd om gegevens te classificeren, de juiste conclusies te trekken of om resultaten te voorspellen. Supervised learning maakt daarbij gebruik van een trainingsset om modellen aan te leren om de gewenste output op te leveren. Deze trainingsdataset bevat invoer en correcte uitvoer. Door de uitvoer van nieuwe invoer te vergelijken met de gewenste uitvoer kan het algoritme (en daarmee het systeem) zich in de tijd verbeteren. Het algoritme past zich aan totdat de fout voldoende is geminimaliseerd. Voorbeelden van supervised machine learning zijn beeld- en spraakherkenning, spamdetectie van je email, de rijdende auto en voorspellende analyse voor bijvoorbeeld de waardeontwikkeling van aandelen.
- Unsupervised machine learning; letterlijk betekent dit ‘ongecontroleerd leren’. Bij deze vorm van machine learning ‘denkt’ het systeem zelf. Op basis van ongestructureerde datasets worden relaties gelegd waarvan je niet wist dat ze bestonden. De machine zal dus data zelfstandig structureren in categorieën of clusters. Er is geen data aanwezig om de uitkomsten of conclusies van het systeem te valideren. Maar dat is juist de bedoeling van unsupervised machine learning. Toepassingen hiervan zie je in de bijvoorbeeld in de genetica door het clusteren van dna patronen om bijvoorbeeld mogelijke ziektebeelden te diagnosticeren voordat iemand überhaupt ziek is geworden. Een meer dagelijkse toepassing is de aanbeveling die je krijgt van Netflix om een film te kijken als je de vorige film hebt afgekeken. Je krijgt zelfs een berekend percentage
 (op basis van beoordelingen van andere gebruikers) te zien waarvan netflix denkt dat je deze film leuk vindt.
(op basis van beoordelingen van andere gebruikers) te zien waarvan netflix denkt dat je deze film leuk vindt. - Reinforcement learning; deze manier van machine learning is gebaseerd op het principe van ’trial and error’. Het algoritme wordt geoptimaliseerd door middel van feedback op eerdere acties en ervaringen. Een indrukwekkend voorbeeld van hoe reinforcement learning al is ingezet, is hoe een computer geleerd heeft hoe hij een level van Super Mario kan uitspelen. Het model heeft geleerd dat hoe verder hij komt in het level, dus hoe meer punten hij behaalt, hoe beter. Met deze informatie start de computer met het spel. Iedere keer dat hij ‘doodgaat’, weet hij dat er op dat punt een verbetering moet plaatsvinden. En wanneer de spelcomputer meer punten behaalt dan tijdens het vorige potje, wordt dit als een beloning gezien. Zo weet het model dat hij deze zetten nog eens kan proberen. Na veel pogingen heeft het model op basis van trial and error geleerd hoe hij Super Mario kan uitspelen.
 (op basis van beoordelingen van andere gebruikers) te zien waarvan netflix denkt dat je deze film leuk vindt.
(op basis van beoordelingen van andere gebruikers) te zien waarvan netflix denkt dat je deze film leuk vindt. Deep learning
Deep learning is in wezen een geavanceerde vorm van machine learning. Het doel van deep learning is om de werking van de hersenen zo goed mogelijk te imiteren. Bij deep learning kan een systeem meerdere vraagstukken en problemen tegelijkertijd oplossen. En kan het systeem zelf prioriteiten stellen. Bij deeplearning vertonen systemen niet alleen vormen van intelligentie. Zij zijn intelligent van zichzelf. Zonder dat de mens daar nog aan te pas komt. Bij deeplearning is het systeem in staat om op basis van externe data zijn eigen algoritme fundamenteel aan te passen. We hebben het dan niet meer over een verbetering van het algoritme (zoals bij machine learning het geval is). Bij deeplearning is een systeem zelf in staat om nieuwe algoritmes te ontwikkelen voor vraagstukken en problemen waar het systeem tegen ‘aanloopt’. Binnen deep learning onderscheiden we twee vormen:
- Intelligente systemen (sterke AI); bij intelligente systemen zijn algoritmen geïnspireerd op de structuur en functie van de hersenen, kunstmatige neurale netwerken genoemd. Intelligente systemen bevatten eigenschappen als luisteren, zien, begrijpen, herkenning, herinneringen, en voorspellen. Deze neurale netwerken weerspiegelen het gedrag van het menselijk brein. Machines die de intelligentie van de mens benaderen zijn er niet en het is maar de vraag of die er ooit zullen komen. Wat niet wegneemt dat specifieke eigenschappen van intelligentie aan systemen zijn toegevoegd. Zo kreeg het algoritme van Google het voor elkaar om op basis van duizenden video’s op YouTube een kat te identificeren, zonder dat de programmeurs van Google het algoritme ‘geleerd’ hebben hoe deze een kat kan herkennen.
- Zelfbewuste systemen (Super AI); we hebben het hier over computers die slimmer zijn dan de mens. Een toekomstbeeld die de fantasie prikkelt. Niet voor niets zijn over dit toekomstbeeld al veel films gemaakt. De machine beschikt naast de eigenschappen van de hersenen van de mens ook over aspecten die de computer zelfbewust maken. Denk daarbij aan eigenschappen als emoties, drijfveren en intuïtie. De zelfbewuste systemen zijn zelf in staat richting te geven aan zijn of haar handelen. Zelfbewuste systemen zijn vooralsnog niet meer dan een hypothetisch concept.
3 Toepassingen in Amsterdam
In de publicatie ‘Amsterdamse Intelligentie‘ van de gemeente Amsterdam wordt uiteengezet hoe de gemeente de voordelen van artificial intelligence inzet voor de uitvoering van haar taken. Artificial intelligence helpt de ambities die Amsterdam heeft te realiseren: een vrije stad, een rechtvaardige stad, een duurzame stad. Artificial intelligence kan helpen het leven van Amsterdammers aangenamer te maken. In Amsterdam zijn zoal de volgende toepassingen van AI in gebruik:
- Categorisering van burgermeldingen met machine learning; om een probleem in de openbare ruimte te melden hoeven Amsterdammers slechts de beschrijving ervan in te typen op de website van de Gemeente Amsterdam. Een algoritme bepaalt op basis van specifieke woorden in het bericht in welke categorie de melding valt, wat ermee gedaan moet worden en door wie. Het melden en oplossen van een probleem gaat zo een stuk makkelijker en sneller.
- Toegang tot milieuzone met kentekendetectie op camera’s; om luchtverontreiniging tegen te gaan heeft Gemeente Amsterdam de binnenstand aangewezen als milieuzone. Vervuilende wagens mogen hier niet meer komen. Slimme camera’s lezen het kenteken van passerende voertuigen, vragen gegevens ervan op en bepalen of het voertuig in de milieuzone mag komen. De foto’s en kentekens van overtreders gaan naar de politie en het Centraal Justitieel
 Incassobureau (CJIB). De overtreder krijgt enige tijd later een boete.
Incassobureau (CJIB). De overtreder krijgt enige tijd later een boete. - Afvaldetectie op beelden; met machine learning technieken zoals neurale netwerken is het mogelijk geworden om computers te leren om bepaalde objecten te herkennen. Binnen de Gemeente Amsterdam is het computersysteem getraind om diverse typen afval te herkennen; van afvalzakken tot kartonnen dozen. Vuilniswagens met camera’s aan boord gaan hiermee afval tellen op straat om zo een real time beeld te vormen van de netheid van Amsterdamse straten.
- Digitale marktmeester voor taxi’s; Amsterdam wil met slimme mobiliteit de stad leefbaar houden. Denk aan het autoluw maken van de binnenstad, de CO2-uitstoot verminderen of de verkeersveiligheid bevorderen. Hierin past ook het beter organiseren van de taximarkt in Amsterdam. De gemeente Amsterdam ontwikkelt een digitale, data-gedreven marktmeester die in sommige gebieden alleen taxi’s toelaat die voldoen aan bepaalde eisen. Bijvoorbeeld of de taxi die besteld is, elektrisch rijdt en dat met camera’s en data ook controleert en handhaaft.
- Voorspellen van parkeerdrukte; parkeerplaatsen in Amsterdam zijn schaars. De Gemeente Amsterdam probeert met machine learning te voorspellen waar parkeergelegenheid is om het beter te organiseren en uiteindelijk Amsterdammers sneller naar een parkeerplaats te begeleiden. Hiervoor wordt data gebruikt van de scanners op auto’s, parkeervergunningen, het wegennetwerk, parkeervakkaarten en diverse gebiedseigenschappen.
- Fraudedetectie wonen; ook woningen zijn schaars in Amsterdam. De gemeente doet er alles aan om illegaal gebruik van woningen – bijvoorbeeld dubbele inschrijvingen, fraude met huursubsidies of overmatige vakantieverhuur – tegen te gaan. In toenemende mate worden handhavers hierbij geholpen door data-analyse en voorspelmodellen. Op basis van een groot aantal factoren wordt de kans op fraude per adres van tevoren berekend. Zo neemt de kans toe dat handhavers bij huisbezoeken inderdaad fraude aantreffen en kunnen optreden.
- Drukte in de stad; Gemeente Amsterdam is bezig om een model te ontwikkelen die de drukte op verschillende locaties in de stad kan voorspellen op basis van diverse datastromen waaronder openbare vervoersinformatie, telcamera’s en evenementen. Dit maakt de kerntaken van de Gemeente zoals het schoonmaken en het veilig houden van stad gemakkelijker.
- AI om discriminatie te detecteren; Amsterdam is een inclusieve stad en bestrijdt actief alle vormen van discriminatie. Daarom ontwikkelt de gemeente een systeem die discriminatie binnen algoritmes bloot legt. Bij machine learning worden relaties gelegd tussen een groot hoeveelheid (data)variabelen. Al dan niet bedoeld sluipt daar nogal eens een vorm van discriminatie in. Stel dat je als gemeente een cultureel centrum wil vestigen. De vestigingsplaats wordt gebaseerd op veel variabelen waaronder die van gemiddelde besteding per inwoner per buurt. Indirect discrimineer je hiermee de arme bewoner. Deze heeft wellicht wel de behoefte maar kan het niet goed betalen.
- Stimuleren van culturele activiteiten; via Facebook Messenger geeft de Nederlandstalige Goochem je tips op maat voor culturele activiteiten in heel Amsterdam en omgeving, op basis van je persoonlijke voorkeuren. Hierdoor kun je nog makkelijker een keuze maken uit het grote aanbod. Goochem toont bovendien alternatieven en minder bekende voorstellingen, optredens of tentoonstellingen in Amsterdam.
 Incassobureau (CJIB). De overtreder krijgt enige tijd later een boete.
Incassobureau (CJIB). De overtreder krijgt enige tijd later een boete.Allemaal toepassingen van kunstmatige intelligentie waarmee de gemeente haar taken beter en goedkoper kan uitvoeren. Tegelijkertijd besteed de gemeente in haar publicatie ook veel aandacht aan de risico’s van het gebruik van AI. De gemeente is, net zoals veel andere organisaties druk doende om principes voor eerlijk en veilig gebruik van KI uit te werken. Zie ook de laatste alinea van deze bijdrage waarin wordt ingegaan op de risico’s en aandachtspunten van het gebruik AI.
4 De Techniek
Om de verschillende vormen en niveaus van artificial intelligence goed te begrijpen is het noodzakelijk om kennis te nemen van de verschillende technieken waarvan kunstmatige intelligentie gebruikt maakt. Waarbij deze technieken soms afzonderlijk en soms in combinatie met elkaar worden gehanteerd om een bepaald probleem/vraagstuk op te lossen dan wel te automatiseren. De meest voorkomende technieken binnen artificial intelligence zijn:
- Rule-based systemen
- Neurale Netwerken
- Diepe Neurale Netwerken
- Neuro Linguïstisch Programmeren (NLP)
- Data & Datamining
4a Rule Based Systemen
Rule based systemen zijn de meest zwakke vorm van artificial intelligence. De samenstelling van dit eenvoudige systeem bestaat uit een reeks door mensen gecodeerde regels die resulteren in vooraf gedefinieerde output. Een rule based systeem is gebaseerd op zogenaamde 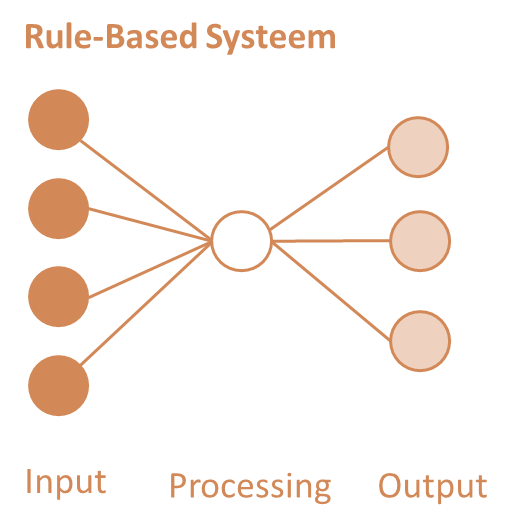 lineaire als-dan constructies. Als de factuur wordt goedgekeurd dan wordt de factuur betaalbaar gesteld.
lineaire als-dan constructies. Als de factuur wordt goedgekeurd dan wordt de factuur betaalbaar gesteld.
- Repeterende taken; de rule based systemen worden gebruikt in situaties waar de taak die ze moeten uitvoeren een sterk repeterend karakter heeft. Als je elke dag het weer voorspelt en je doet dit elke dag op dezelfde manier (als-dan) dan kun je de specifieke kennis van de mens gebruiken om het voorspellen te automatiseren. De kennis van de mens wordt gecodeerd in als-dan regels in een computer programma (systeem).
- Deterministisch; computerprogramma’s (algoritmes) die zijn gebaseerd op als-dan regels (oorzaak-gevolg) zijn onveranderlijk. Een op regels gebaseerd systeem kan alleen taken uitvoeren waarvoor het is geprogrammeerd. En niets anders. Rule based systemen zijn geen zelflerende systemen die eigenstandig hun algoritme kunnen aanpassen. Alleen met tussenkomst van de mens kan een taak in het systeem worden gewijzigd of toegevoegd.
- Toepassingen; klassiek voorbeeld van de rule based systemen zijn de eerdergenoemde expert- of kennissystemen. Systemen die zijn ontwikkeld om één taak uit te voeren. Dat kan gaan om de bekende schaakcomputer, een boekhoudprogramma of een planningssysteem. Overigens kunnen rule based systemen zeer complex zijn met wel duizenden regels. Denk bijvoorbeeld aan computerprogramma’s die het weer voorspellen. Maar ook deze complexte systemen blijven ruled based systemen omdat ze zijn gebaseerd op als-dan regels en niet zelflerend zijn.
- Voorbeeld; in de figuur hiernaast is de rule based systeem schematisch weergegeven op basis van de basisprincipe van elk computerprogramma: Input-process-output. Een voorbeeld is een boekhoudprogramma. Input voor dit programma zijn salariskosten die betaald moeten worden, opbrengsten die worden gegenereerd en winst die moet worden uitbetaald. Op basis van de coderingsregels van het boekhoudprogramma wordt deze input verwerkt (processing). En bestaat de output uit een winst- en verliesrekening, een balans en een kasstroomoverzicht.
Deze zogenaamde rule-based systemen zijn relatief eenvoudig. Maar daar is niks mis mee. Kijk maar eens naar hoeveel welvaart deze zogenaamde expertsystemen de mens heeft gebracht. Rule based-systemen voorzien in de behoefte om taken met vaste regels en een repeterend karakter te automatiseren.
4b Neuraal Netwerk
Een neuraal netwerk is dé tegenhanger van rule-based systemen. Rule-based systemen zijn programma’s die de gecodeerde instructies letterlijk uitvoeren (lineaire functies). Daarmee zijn rule-based systemen statisch. De algoritmes van het systeem veranderen alleen als de codering door de mens wordt aangepast. Neurale netwerken daarentegen zijn losjes gemodelleerd naar het menselijk brein. Het menselijk brein is buitengewoon complex en krachtiger dan elke  computer die we heden ten dage kennen. Waarbij de innerlijke werking van het menselijk brein vaak wordt gemodelleerd rond het concept van neuronen. Het menselijk brein bevat miljarden van zulke neuronen, die via netwerken allemaal met elkaar verbonden zijn. Waarbij de uitkomst van een neuroon weer geldt als prikkel voor andere neuronen. Dit proces herhaalt zich (in duizendste van seconden) totdat een extern signaal, zoals bijvoorbeeld een geluid, door de hersenen goed geïnterpreteerd wordt. Op basis waarvan het brein, indien nodig, opdracht geeft tot actie aan andere neuronen. Neuronen die bijvoorbeeld gericht zijn op het aansturen van de spieren. Denk bijvoorbeeld aan de wekker die in de ochtend afgaat waarna je opstaat en het koffiezetapparaat aan zet.
computer die we heden ten dage kennen. Waarbij de innerlijke werking van het menselijk brein vaak wordt gemodelleerd rond het concept van neuronen. Het menselijk brein bevat miljarden van zulke neuronen, die via netwerken allemaal met elkaar verbonden zijn. Waarbij de uitkomst van een neuroon weer geldt als prikkel voor andere neuronen. Dit proces herhaalt zich (in duizendste van seconden) totdat een extern signaal, zoals bijvoorbeeld een geluid, door de hersenen goed geïnterpreteerd wordt. Op basis waarvan het brein, indien nodig, opdracht geeft tot actie aan andere neuronen. Neuronen die bijvoorbeeld gericht zijn op het aansturen van de spieren. Denk bijvoorbeeld aan de wekker die in de ochtend afgaat waarna je opstaat en het koffiezetapparaat aan zet.
Kunstmatige neurale netwerken
Bij kunstmatige intelligentie dat is gebaseerd op een neuraal netwerk worden de menselijke neuronen in een computerprogramma vervangen door (niet lineaire) functies. Waarbij input tegelijkertijd door verschillende functies tot output wordt verwerkt. Welke functie welke input verwerkt hangt af van hoe de relaties tussen de verschillende functies in de codering zijn aangebracht. Kenmerken van een neuraal netwerk zijn:
- Weging van input (gewichten); belangrijk kenmerk van een neuraal netwerk is dat de verschillende functies onafhankelijk van elkaar tegelijkertijd uitgevoerd kunnen worden. Elke functie reageert in meer of mindere (of helemaal niet) op bepaalde prikkels. Dus bij het uitwerken van het netwerk van functies moet worden bepaald of en hoe belangrijk welke input (inkomend bericht) is voor welke functie. Voor het bepalen of op een afbeelding een olifant of hond staat is het aantal poten voor het programma niet relevant. Terwijl het hebben van een slurf dat wel is.
- Grenswaarde van input; naast het relatieve belang van elke mogelijke input voor een functie (zodat een evenwichtige berekening kan worden gemaakt) is het van belang, net zoals het menselijk brein dat doet, om grenswaarden van de input te definiëren. Als een bepaalde input niet boven een grenswaarde uitkomt negeert de de functie de input.
 Zo wordt je in de nacht niet wakker van omgevingsgeluiden omdat deze de drempelwaarde niet overstijgen. En wordt je wel wakker van de wekker of van een kind dat schreeuwt omdat het een nachtmerrie heeft.
Zo wordt je in de nacht niet wakker van omgevingsgeluiden omdat deze de drempelwaarde niet overstijgen. En wordt je wel wakker van de wekker of van een kind dat schreeuwt omdat het een nachtmerrie heeft. - Learning by example (trainingsets); in tegenstelling tot een rule-based systeem, waar de opeenvolgende stappen zijn voorgeprogrammeerd, leert een computer gebaseerd op een neuraal netwerk door het zien van voorbeelden. Net zoals het kind leert van het voorbeeld dat de ouders geven. Op basis van een groot aantal afbeeldingen leert de computer hoe een olifant eruit ziet. Waarbij de onderscheidende factoren van de olifant zoals de slurf, slagtangen en zijn grote oren expliciet in de voorbeelden naar voren komen. Hoe groter de trainingsets hoe nauwkeuriger de computer kan aangeven of er een olifant op de afbeelding staat of niet.
- Zelflerend vermogen; nadat de computer feedback krijgt op de uitkomsten van zijn voorspelling wordt de trainingsset steeds groter. De computer herkent patronen op basis waarvan hij verkeerde voorspellingen heeft gedaan en past de functies (algoritmes) aan zodat de voorspelling steeds beter wordt. Denk bijvoorbeeld aan de spam filter. De spamfilter stelt vast welke mail door de gebruiker direct naar de de prullenbak wordt verplaatst. De spamfilter analyseert deze mails (bijvoorbeeld op afzender of taalstructuur) om vervolgens het algoritme van de spamfilter hierop aan te passen.
 Zo wordt je in de nacht niet wakker van omgevingsgeluiden omdat deze de drempelwaarde niet overstijgen. En wordt je wel wakker van de wekker of van een kind dat schreeuwt omdat het een nachtmerrie heeft.
Zo wordt je in de nacht niet wakker van omgevingsgeluiden omdat deze de drempelwaarde niet overstijgen. En wordt je wel wakker van de wekker of van een kind dat schreeuwt omdat het een nachtmerrie heeft.Met neurale netwerken zijn computers in staat om op basis van grote hoeveelheden data patronen te ontdekken waarmee ze vervolgens hun eigen algoritme (computerprogramma) aanpassen. Denk daarbij aan toepassingen als Netflix (aanbevelingen voor nieuwe serie), Google (het rangschikken van meeste relevante content), spraak- en gezichtsherkenning en de zelfrijdende auto. Neurale netwerken staan daarmee aan de basis van het zogenaamde machine learning. Toch vallen neurale netwerken vooralsnog onder de definitie van zwakke artificial intelligence. Dit omdat ze tot op heden worden ingezet voor het oplossen van één vraagstuk. Computers kunnen óf gezichten herkennen, óf schaken óf een ziektebeeld op basis van aantal rode cellen diagnosticeren. Terwijl het menselijk brein deze vraagstukken tegelijkertijd naast elkaar (tot een bepaalde hoogte) kan oplossen.
4c Diepe Neurale Netwerken
Bij een diep neuraal netwerk wordt een probleem of vraagstuk in meerdere lagen opgelost. Elke laag vertegenwoordigt een bepaalde functie. Elke laag die wordt toegevoegd gebruikt de uitkomst uit de voorgaande lagen. Stel je voor dat je het algoritme wilt leren om een afbeelding van een olifant te leren herkennen. Je kunt dan bijvoorbeeld in de eerste laag het algoritme verschillende kleuren laten herkennen. De tweede laag kan vormen  herkennen (vierkant, rechthoek, cirkel, ovaal). De derde laag herkent op basis van de kleur en de vorm of het om de poten, gezicht of lichaam van het dier gaat. In de vierde laag worden de lichaamsdelen gecombineerd met de kleur om uiteindelijk te bepalen of het om een olifant gaat of niet.
herkennen (vierkant, rechthoek, cirkel, ovaal). De derde laag herkent op basis van de kleur en de vorm of het om de poten, gezicht of lichaam van het dier gaat. In de vierde laag worden de lichaamsdelen gecombineerd met de kleur om uiteindelijk te bepalen of het om een olifant gaat of niet.
Er zijn inmiddels kunstmatige neurale netwerken ontwikkeld met meer dan 100 lagen. Waarbij geldt hoe meer lagen een neuraal netwerk heeft hoe nauwkeuriger de uitkomst van het vraagstuk zal zijn. Althans als je de relaties tussen de verschillende functies goed in het algoritme vastlegt. Maar wees je er wel van bewust dat als elke laag 10 functies heeft er een extreem groot aantal verbindingen ontstaat. Daar zijn diepe neurale netwerken complex die extreem veel rekencapaciteit nodig hebben. Dat is ook de reden dat deze diepe neurale netwerken ook wel black box algoritmen worden genoemd. De interne samenhang en afhankelijkheid tussen de verschillende neuronen (functies) is niet meer uit te leggen. Dat is ook de reden dan vooralsnog alleen Big Tech bedrijven gebruik maken van diepe neurale netwerken. Maar het moge duidelijk zijn dat diepe neurale netwerken de toekomst zijn van artificial intelligence.
4d Neuro Linguïstisch Programmeren (NLP)
Binnen het vakgebied van artificial intelligence richt het Neuro Linguïstisch Programmeren (NLP) zich op de interactie tussen de computer en de mens. Met behulp van NLP kan de mens met de computer communiceren. NLP omvat technieken waarbij de computer spraak (klanken) of teksten (karakters) vertaald in nulletjes en eentjes die de computer begrijpt (en visa versa).
Tot het jaar 2000 had NLP een sterk linguïstisch karakter. Dat wil zeggen dat computers werd geleerd om de taalstructuur van de mens te ontleden en te begrijpen. Vandaag de dag heeft NLP een veel minder sterk linguïstisch karakter. Met de opkomst van neurale netwerken en Big Data zijn computers veel beter in staat om spraak en tekst goed te kunnen interpreteren. Niet de taalstructuur van de mens maar zelflerende systemen in combinatie met Big Data (met oneindig hoeveelheid voorbeelden)  bepalen de interacties tussen de computer en de mens. Voorbeelden van toepassing van NLP zijn:
bepalen de interacties tussen de computer en de mens. Voorbeelden van toepassing van NLP zijn:
- Spraakassistent; elke ‘zichzelf respecterende’ telefoon of tablet beschikt tegenwoordig over een spraakassistent. Denk daarbij bijvoorbeeld aan Siri van Apple. Je kunt aan Siri van alles vragen, bijvoorbeeld “Gaat het vandaag regenen?” Siri zet de ingesproken opdrachten om in computertaal waarna de telefoon (computer) de taak uitvoert en jou het antwoord op de vraag geeft.
- Samenvatten teksten & tekst suggesties; we kennen allemaal de ‘autocomplete’ functies in WhatsApp en Word van Microsoft office. De autocomplete functie is een programma (algoritme) die op basis van een analyse van enorm grote hoeveelheden teksten het volgende woord kan voorspellen. Dit algoritme is een zelflerend systeem die op basis van goede (de gebruiker neemt de suggestie over) en foute voorspellingen (de gebruiker neemt de tekst suggestie niet over) het algoritme aanpast.
- Spamfilters; elk mailprogramma beschikt over een spamfilter. Met behulp van kunstmatige intelligentie worden ongewenste mails gefilterd op basis van woordgebruik en schrijfstijl. Spamfilters zijn zelflerende systemen. Als bepaalde mailberichten door gebruikers direct in de prullenbak worden gegooid dan zal het algoritme van de spamfilter dit signaleren. Het spamfilter analyseert de mail op woordgebruik en taalstructuur en past het algoritme van de spamfilter aan.
- Classificatie van berichten; op basis van woordherkenning wordt een vraag of klacht van een klant direct doorgezet naar de goede afdeling zonder dat de klant zelf hoeft aan te geven om wat voor probleem of vraag het gaat. Op basis van een analyse van de woorden die de klant of burger in zijn bericht opneemt weet het programma welke afdeling de vraag of probleem het best kan oplossen. Zo kunnen burgers in Amsterdam op de website van de gemeente een bericht achterlaten dat er een stoeptegel los zit. De opmerking wordt dan direct doorgezet naar de afdeling Beheer en Onderhoud van de gemeente.
- Sentimentanalyse; met NLP worden analyses uitgevoerd, bijvoorbeeld door bedrijven, om vast te stellen hoe de klanten over bijvoorbeeld een specifiek product denken. Mails van klanten of berichten op social media worden gescand op emotionele uitingen. Gescand wordt op woorden als “belachelijk, goed, slecht, onzin, fantastisch, etc.”. Op basis van sentimentanalyse kan een bedrijf in kaart brengen waarover de klant (on)tevreden is en haar processen daarop aanpassen.
Binnen het vakgebied neuro linguïstisch programmeren is het GPT-3 model (Generative Pre-trained Transformer) van Elon Musk de laatste revolutionaire ontwikkeling. Dit model is zo enorm krachtig dat het integrale teksten kan genereren met daarin samenhangende tegenargumenten van een betoog van een mens. Teksten die veelal beter zijn dan de mens die zelf kan maken. Ongekende mogelijkheden dus met NLP. Met alle risico’s van dien.
4e Big Data & Datamining
Big data leidt in combinatie met datamining tot nieuwe inzichten. Statistische technieken die worden losgelaten op (gekoppelde) databases leggen patronen bloot tussen gegevens die het menselijk brein (vanwege beperkte verwerkingscapaciteit) zelf niet kan constateren. Datamining is daarmee een onmisbare techniek binnen artificial intelligence. Bij lerende systemen zijn computerprogramma’s in staat om op basis van deze nieuwe inzichten zichzelf te verbeteren.
- Big Data; de hoeveelheid data die opgeslagen wordt, groeit exponentieel. Dit komt doordat consumenten, bedrijven en overheden steeds meer data opslaan in de vorm van bestanden, foto’s en films maar ook doordat er steeds meer computersystemen of apparaten zelf data verzamelen, opslaan en uitwisselen. Denk bijvoorbeeld aan de zelfrijdende auto die helemaal vol zit met sensoren.
- Datamining; is het gericht zoeken naar (statistische) verbanden tussen verschillende gegevensverzamelingen (Big Data) met als doel profielen op te stellen voor wetenschappelijk, journalistiek of commercieel gebruik. De toenemende verwerkingskracht en snelheid van computers zorgt ervoor dat datamining de laatste decennia een hoge vlucht heeft genomen.
- Handhavingsorganisaties; de Politie, de Belastingdienst en Inspecties delen steeds vaker informatie (datasets) zodat zij op basis van risicoprofielen gericht actie kunnen ondernemen. Met als doel om de beperkte middelen zo effectief mogelijk in te zetten. Als je bijvoorbeeld een bekende bent van de politie is dat wellicht voor de Belastingdienst reden om jouw belastingaangifte extra goed te controleren.
- Commerciële toepassingen; door relaties te leggen van de verkoop van verschillende productgroepen is het mogelijk om gerichter in te kopen en om zo verspilling tegen te gaan. En zo analyseren bedrijven als Walmart het aankoopgedrag van klanten zodat zij hun marketing hierop af kunnen stemmen. Als je een gieter koopt is de kans groot dat je diezelfde week een folder ontvangt met aanbiedingen hoe je je tuin nog beter kunt onderhouden.
Uncle Sam is wachting you! Big Data leidt bij mensen soms tot een onbehagelijk gevoel dat alles wat zij doen wordt vastgelegd. En dat niet duidelijk is wie daar wat mee kan doen. Verder leidt Big Data leidt soms tot vervelende situaties. De Amerikaanse winkelketen Target kwam in het nieuws, doordat ze op basis van statistische analyse van de veranderingen in het aankoopgedrag van haar klanten folders over babybenodigdheden toestuurde naar (statistisch bewezen….) zwangere vrouwen. Sommige vrouwen waren niet zwanger, sommige vrouwen waren wel zwanger maar daarvan wist de partner het nog niet van en bij enkele vrouwen was sprake van een miskraam.
5 Risico’s & Aandachtspunten Kunstmatige Intelligentie
Met de combinatie van big data, ongekende rekencapaciteit en zelflerende algoritmes komen we met kunstmatige intelligentie in de fase van zelflerende systemen. Zelflerende systemen die ‘hun eigen leven beginnen te leiden’ bieden oneindige mogelijkheden die die het welzijn en de welvaart kunnen verbeteren. Onze manier van leven gaat hierdoor, nog meer dan nu het geval is, veranderen. Sommige deskundigen zijn zelfs van mening dat de zelflerende systemen een ontwrichtende impact gaan krijgen op de samenleving. Althans als je geen oog hebt voor de risico’s die inherent zijn aan kunstmatige intelligentie.
- Verantwoordelijkheidsvraagstuk; hoe verandert het begrip verantwoordelijkheid als je te maken hebt met artificial intelligence? Wie is verantwoordelijk als de zelfrijdende auto een ongeluk veroorzaakt? Zelfrijdende auto’s zullen in de toekomst veiliger zijn dan door de mens bestuurde auto’s. Maar als zich dan toch een ongeluk voordoet. Wie draagt dan de verantwoordelijkheid? De mens (die niet meer zelf aan het stuur zit), de auto (meer specifiek het algoritme in de auto) of de producent (die het algoritme heeft gemaakt)?
- Big Brother is Wachting You; het gebruik van artificial intelligence in het algemeen en van Big Data in het bijzonder maakt inbreuk op je privacy of zelfs op jouw persoonlijke vrijheid. Dit is afhankelijk van hoe de informatie door bedrijven of overheden wordt ingezet. China kent bijvoorbeeld een puntensysteem op basis waarvan goed gedrag bij de burgers wordt gestimuleerd. De gemeentelijke basisadministraties is gekoppeld aan het gebruik van social media, aankopen bij webshops en aan gezichtsherkenningscamera’s op straat. Als je door rood stoplicht loopt wordt dat geregistreerd door camera’s en krijg je minpunten. De vraag is of je hiermee alleen goed
 gedrag wil stimuleren of met deze kunstmatige intelligentie minderheden en critici wil onderdrukken?
gedrag wil stimuleren of met deze kunstmatige intelligentie minderheden en critici wil onderdrukken? - Polarisatie en ontwrichting van de maatschappij; facebook, twitter en google spelen met hun zelflerende algoritmes in op jou persoonlijke voorkeuren. Dit heeft zo zijn voordelen. Als je een computer koopt wordt je eraan ‘herinnerd’ ook een muis of speaker te kopen. Dan is handig. Maar als al het nieuws wordt gefilterd op jouw voorkeuren kom je niet meer in aanraking met andere argumenten of meningen. Gebruikers komen in een informatiebubbel terecht wat bijvoorbeeld in Amerika bijdraagt aan de polarisatie van de maatschappij.
- Fake-news; een ander risico van kunstmatige intelligentie is het zogenaamde fake news die niet van echt is te onderscheiden. Het is bijvoorbeeld relatief eenvoudig om de president van de Verenigde Staten in een video woorden in de mond te leggen die hij niet heeft gezegd (is echt gebeurd). Dit met alle risico’s van dien. In het ergste geval kan dit tot een internationale incidenten leiden.
- Menselijke maat; gezinnen die geheel terecht kinderopvangtoeslag ontvingen, werden door de belastingdienst beoordeeld als mogelijke fraudegevallen. In sommige gevallen leidde dit tot het geautomatiseerd stopzetten van de toeslag en terugvorderingen. Het bleek een fout te zijn. Een fout in een algoritme? Fout in de data? In dit voorbeeld gaat het om het onterecht toevoegen van nationaliteit aan de data, wat tot etnisch profileren heeft geleid.
- Gezond verstand; kunstmatige intelligentie geeft uitkomsten op basis van duizenden, miljoenen voorbeelden die onder gelijksoortige omstandigheden tot stand zijn gekomen. En daarmee is de nauwkeurigheid van de uitkomsten hoog. Maar dan heb je nog altijd het gezond verstand als er een omstandigheid voordoet die niet in het model zit opgenomen. Een zelfrijdende auto zal waarschijnlijk direct stoppen als er een luchtballon vlak boven de weg hangt. Terwijl de mens op basis van de richting, de hoogte en snelheid van de luchtballon geen enkel gevaar ziet.
- Politieke besluitvorming; kunstmatige intelligentie kan zowel bij de voorbereiding van besluitvorming als bij de uitvoering ervan een belangrijke rol spelen. Het is uitdrukkelijk niet de bedoeling dat programmeurs of data-engineers (al dan niet bewust) beleid maken. Denk bijvoorbeeld aan het plaatsen van een culturele instelling. Op basis van een algoritme kom je op basis van het besteedbaar inkomen al snel tot de conclusie dat kans van slagen het grootst zal zijn in een ‘rijke buurt’. De vraag is echter of je vanuit een bepaalde gedachtegoed deze culturele instelling juist in een ‘arme buurt’ wil vestigen om participatie te bevorderen en armoede te bestrijden.
 gedrag wil stimuleren of met deze kunstmatige intelligentie minderheden en critici wil onderdrukken?
gedrag wil stimuleren of met deze kunstmatige intelligentie minderheden en critici wil onderdrukken? Kortom; kunstmatige intelligentie leidt in potentie tot een hogere welvaart en een beter welzijn voor de mens. De vraag is waar de balans ligt tussen de voordelen en mogelijkheden van kunstmatige intelligentie en de risico’s ervan. Hoe voorkomen we dat KI discrimineert of groepen uitsluit? Dat KI niet alleen voorbehouden is aan diegenen die het kunnen betalen? Of dat kunstmatige intelligentie de privacy schendt of nog erger vrijheden inperkt. Dit vraagstuk heeft de aandacht van beleidsmakers die kaders opstellen voor gebruik van kunstmatige intelligentie. Een goed voorbeeld hiervan is de Europese regelgeving rondom privacy die in Nederland is uitgewerkt in de Algemene Verordening Gegevensbescherming (AVG).
wat zijn de moeilijkste factoren om te willen veranderen als mens zijnde